Intro
If you’re operating in a SIAM operating model, you’ll soon hit the challenge of building an effective CMDB
Unfortunately, there’s no one-size-fits-all solution. Our white paper provides invaluable advice about how to build a CMDB in a SIAM environment.
Since the early days of ITIL™, organisations have strived to realise the dream of the Configuration Management database (CMDB).
This is described as a virtual repository which enabled IT organisations to store information about IT assets, IT services, users, business units and a whole host of other Configuration Items (CIs). Critically, the concept went beyond that of a list of assets, but also encompassed the relationships between each of the entities in the CMDB, thus creating a logical database of relationships between, say, IT services and the business units who consume them, or applications and the underlying infrastructure which supports them. The advent of multi-supplier operating models, embodied within the Service Integration & Management (SIAM) framework, made the dream of the CMDB seem further away than ever.
The challenges of sharing large quantities of asset data from multiple service providers are exacerbated by the following factors:
- The different systems in use within each of the service providers
- The lack of a single naming convention for CMDB data entities
- The lack of an overarching data model to support this
- The lack of a simple means of integrating CMDB data across various systems
- Setting an appropriate scope to the data that is made available from service providers
- The variety of underpinning governance and maintenance processes from one organisation to another
- The reluctance of service providers to each use the same tool for CMDB data
- This complexity and challenge often prevents organisations from successfully deploying a CMDB when they have embarked upon a multi-vendor, SIAM operating model
However, there are some simple principles that can be adopted which will simplify the introduction of this content, and using practical experience, this paper will explore some of the tried and tested techniques that enable organisations to derive benefit from a relational database of business and IT-related data.
1. Undertake a fact-finding phase
Many organisations find that they often have lots of disparate repositories, in Sharepoint sites, Access databases and Excel spreadsheets, which contain data that could be useful to the rest of the organisation as part of the CMDB. Using the data model and the requirements as a guide, undertake a “data amnesty” amongst the IT workforce, gathering existing databases which could form part of the new CMDB.
In our experience, it is possible to incorporate separate data sources such as those described below:
- Business Service Catalogue
- Applications list (or ability to discover)
- Business Units data
- Location data
- Business continuity / recovery plans
The fact-finding phase should also seek to establish what data any third-party service providers may be willing or contractually obligated to provide. Commonly, there are no contractual obligations that describe the need for data to be shared. If this is the case, it is likely that your CMDB will not be able to make use of service provider’s configuration data.
2. Ensure you have the basic building blocks
As mentioned later in this document, hardware and software assets can commonly be discovered or audited. However, there are some basic datasets that cannot. I refer to these as “logical CIs”, and they are critical to the value of
the CMDB to the business.
The data sets below are truly vital. I have provided a brief description of each.
Business Service Catalogue
This provides details of the services IT provides to the business. For example, the Finance service, the HR service, the Logistics service. A service in this context can comprise a number of disparate applications or systems which come together to support a business process and/or deliver a process outcome.
Applications list
I referenced application discovery later in this document. However, at the very minimum, having a list of the current applications will be a great starting point.
Business Units data
Details of the various business units / departments in the organisation will be valuable, particularly if it is possible to relate user, service and application data to this dataset. This can then be used to undertake basic impact analysis for incidents, problems and prospective changes.
Location data
A simple list of the locations with the organisation, can also be used for impact
analysis, if used in the manner described above.
Business continuity / recovery plans
Business continuity or disaster recovery documentation often contains significant data on how the business consume the IT services, and can be a valuable source of content.
3. Set the data bar at a realistic level
Arguably, some consideration must be given as to whether data from the service providers within the SIAM eco-system is actually required. If the customer is buying an outcomes-based contract, should they actually care about the details of the underpinning infrastructure which delivers it?
When adding cloud service providers to the picture, it is very difficult to obtain detailed infrastructure information about their services, although some offer the ability to discover basic details for CMDB population. The key here is to set the required level of detail at the most practical and achievable, avoiding the
requirement for service providers to expose more details of their infrastructure than they are able to.
4. Design the end state
It’s an old adage to “begin with the end in mind”, but this is critical in the development of a CMDB. We’d strongly encourage the capture of requirements from key stakeholders in IT to determine what they need. The requirements
should then be prioritised, and ranked for simplicity, business benefit, cost to implement, and other factors as necessary, to determine the scope of the program.
The design phase should include the development of a high-level data model. This need not be overly onerous, in fact, many organisations choose to build this within their CMDB toolset as opposed to producing detailed designs in say, Microsoft Visio.
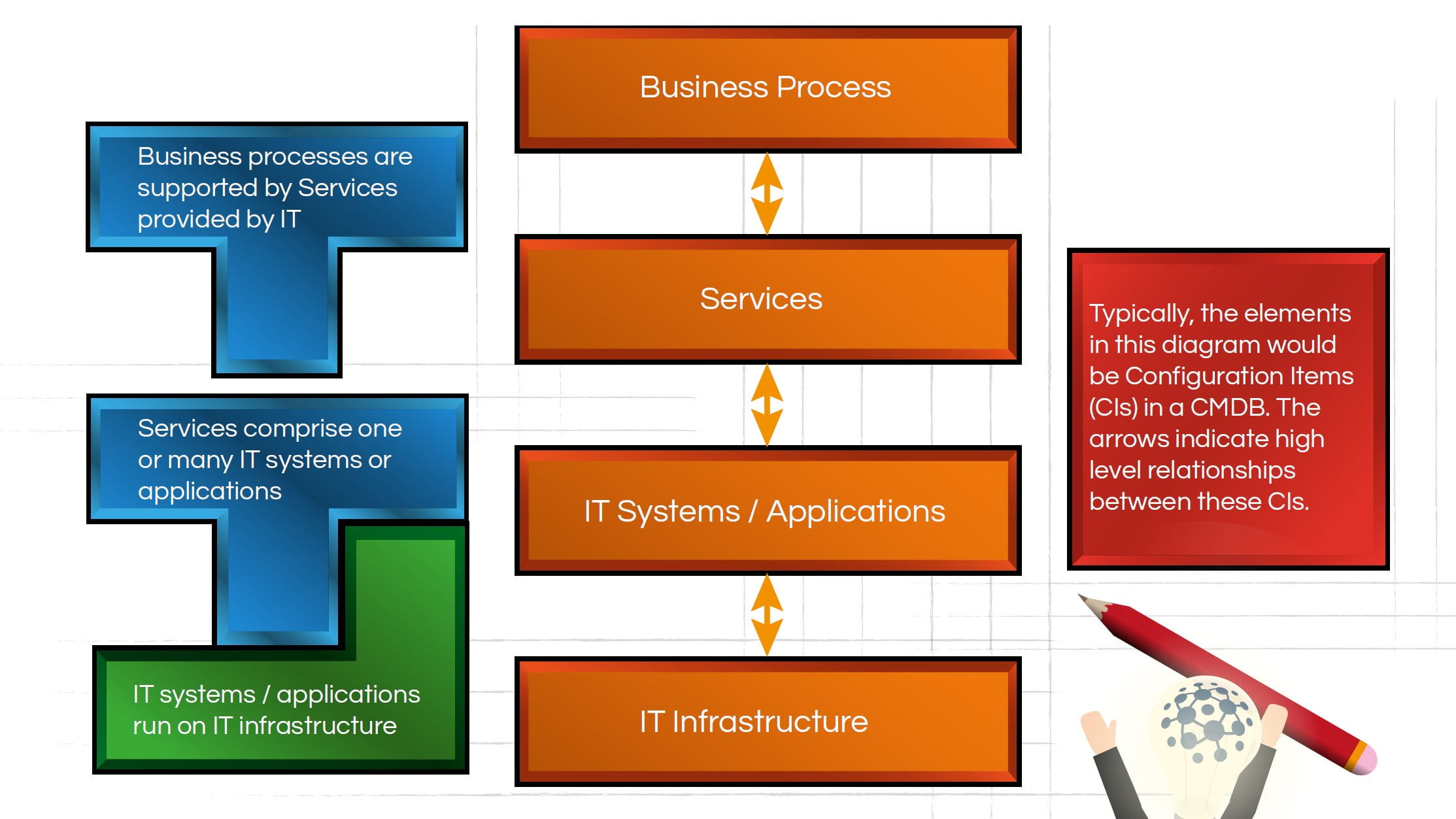
As a starting point, the diagram below gives the very high-level headings from which the data model can be derived. Each breaks down into a number of sub-headings. For example, infrastructure can be broken down into server, desktop, software, etc. These are generally referred to as Configuration Items (CIs). Each CI will contain information that describes it, for example, its unique reference, its version, etc. This data is commonly referred to as an attribute of a CI.
One word of warning here though. Given the complexity of the SIAM eco-system, it is likely that third-party service providers will have their own configuration data for the elements of the service they run. There is a risk that the CMDB could become unwieldy if data from their entire SIAM eco-system is to be populated. It will be necessary to find a sensible cut-off point where some data remains in the service provider’s CMDB, but is accessible if required. Other data can be exported and populated in the CMDB if it is required. Rigorous analysis of the proposed data model will be required to help achieve a pragmatic approach here.
5. Consider how the data will be maintained in an accurate state
CMDB data accuracy is vital. Basing a decision to approve a change or recover an incident on inaccurate information could have serious consequences. So, as part of the data model verification exercise, the means by which the data will be kept in an accurate state should also be established.
This may involve a combination of the following methods:

6. Use discovery and dependency mapping technology
There are a number of basic asset discovery tools on the market which can capture basic asset information. These can be supplemented by more sophisticated dependency mapping tools, which will not only discover assets, but will also monitor which assets are communicating with other assets, and through analysis of the nature of the communication, they will establish dependencies between the assets; in simple terms, relationships between Configuration Items in the CMDB.
7. Considering data integration / exchange technology
In response to the complexity involved in developing a CMDB in today’s complex models, many data integration / exchange technologies have been developed. Essentially, these maintain a mapping between data fields in different tools, and provide a transport mechanism whereby changes in one system are reflected in another.
These can be extremely valuable, particularly where third parties have their own CMDBs, and access is required to a subset of this. Explore the market offerings in this area to find the one most suitable for your requirements.
8. Develop data model governance
The data model provides valuable guidance on the CMDB contents, the level of detail being stored and is ultimately designed to meet the needs of the business. Over time, it is common for these design principles to change, and commonly the original ideals and structure of the data model are lost. Data model governance is therefore critical to ensure that the data model is controlled, and also to provide a structured process by which it can evolve over time, in response to changing business requirements.
9. Deliver in phases
Undoubtedly there will be a huge volume of CMDB requirements. As mentioned earlier these should be prioritised and development phases scoped. The scope of each phase should deliver incremental business benefit to the various stakeholder groups involved in the data capture exercise.
10. Don’t forget to bring the people along for the journey
The introduction of a CMDB should be treated like any other project, and therefore it must have a business change component. In the case of CMDB data, organisations often find themselves fighting against a recurring problem. Knowledge is power. Giving up control of the spreadsheet or Sharepoint site, and exporting this data into a more open CMDB is often a challenge. Ensure that there is a business change program that supports the required behavioural changes. For example, this might involve the setting of new policies relating to data storage, and training for those involved to use the corporate CMDB, as opposed to developing local data storage systems.
11. Conduct a Benefits Realisation exercise
As mentioned above, delivery of the CMDB benefits will be on a phased basis, based upon the prioritised requirements captured at the start of the project.
Typically, organisations with access to configuration data are able to:
- Undertake more accurate impact analysis for incidents, problems and prospective changes
- Improve the accuracy of cross-charging for IT services
- Validate the bills provided by 3rd party service providers
- Produce more accurate business cases for technology projects
- Realise efficiencies through the introduction of a single source of record
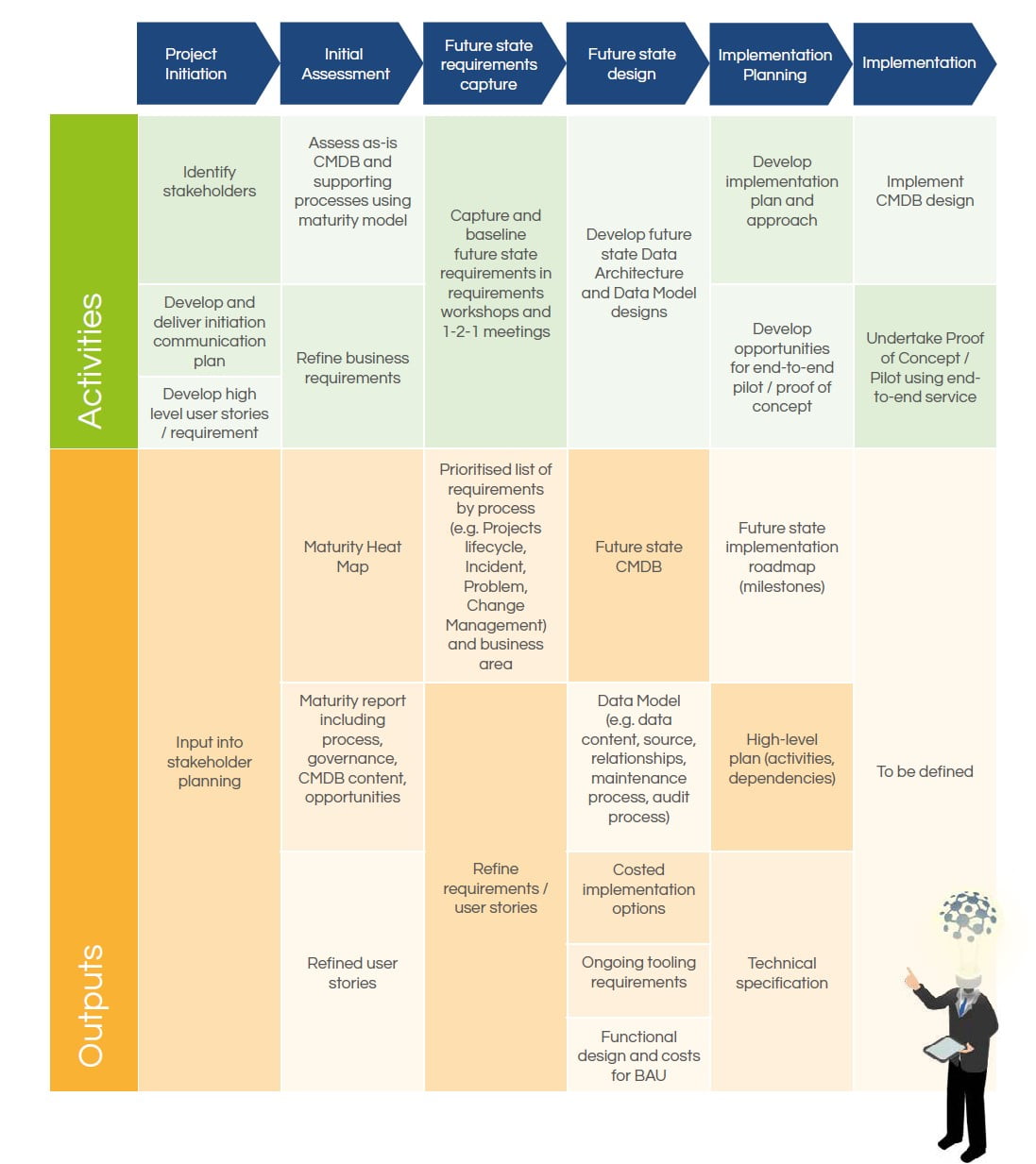
How do organisations typically structure their projects?
We have provided below an outline plan we produced for one of our customers. This is obviously very high level, but it should give an indication of the various phases involved.
Conclusion
In our experience of working in IT Service Management for over 30 years, we have found that organisations often have a desire to improve the maturity of their Configuration Management Database (CMDB).
However, this is often impeded by:
- The lack of CMDB design expertise
- The absence of a CMDB improvement roadmap
- The complexity involved in a multi-vendor / SIAM (Service Integration & Management) operating model
These challenges often inhibit progress, and this inertia means that the benefits of a CMDB are seldom realised.
The success of any CMDB project will be determined by the quality of the requirements captured at the outset, and the classification of these requirements to determine a realistic scope.
Undertaking a short CMDB readiness exercise, to understand what data exists today, will provide the ability to undertake a gap analysis between this and the business requirements.
Please contact us to discuss your specific challenges.




